使用Pandas做数据分析时,首先要读取数据。Pandas常用的读取文件有:
- pd.read_csv() 用于读取csv格式文件
- pd.read_excel() 用于读取xls和xlsx格式文件
- pd.read_json() 用于读取json格式文件
- pd.read_table() 用于读取txt格式文件
CSV文件读取
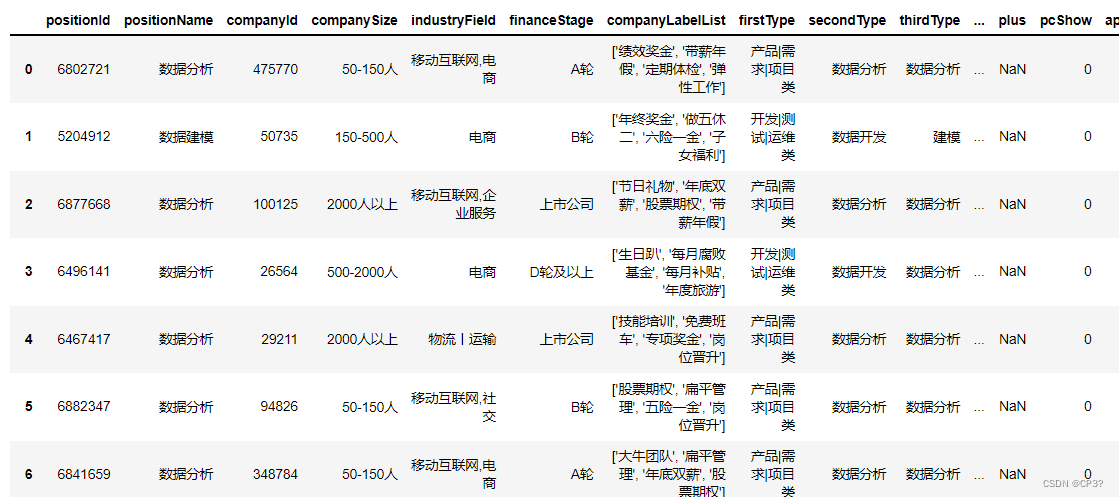
import pandas as pd df = pd.read_csv("D:/pandas/TOP250.xlsx")#某csv文件首先,调用pandas模块,通过.read_csv()括号内加文件路径读取文件,展示部分结果图,如下:
有时,我们并不会读取所有列或所有行,而是有条件的筛选。这时,我们可以在读取时通过增加代码进行筛选。
一:指定行列
norws=n 表示读取前n行
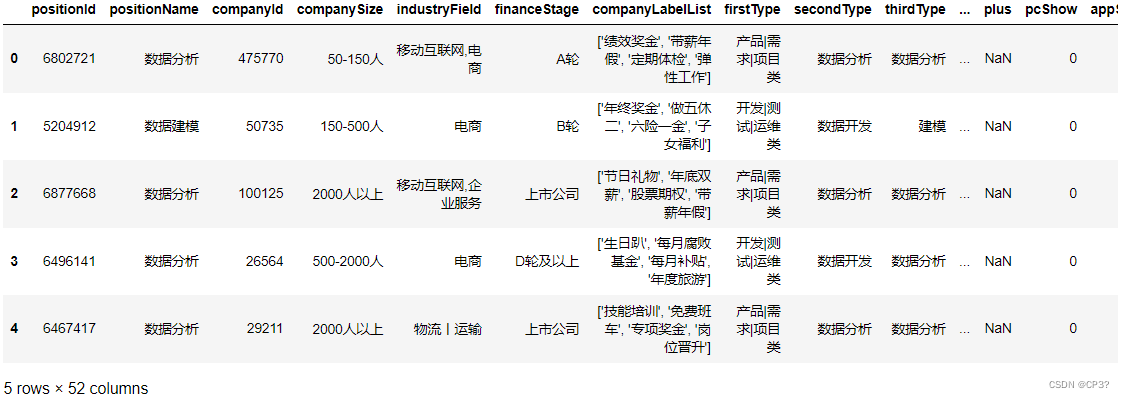
df = pd.read_csv("D:/pandas/TOP250.xlsx",nrows=5)上述代码表示读取csv文件的前5行,得到的结果如下图:
skiprows = n,n可以是数值也可以是列表,表示跳过某些行
df = pd.read_csv("D:/pandas/TOP250.xlsx",skiprows=3) #表示跳过第三行,读取除了第三行以外的行 df = pd.read_csv("D:/pandas/TOP250.xlsx",skiprows=[i for i in range(1,11)]) #表示跳过前10行 df = pd.read_csv("D:/pandas/TOP250.xlsx",skiprows=lambda x: x % 2) #表示跳过偶数行,读取奇数行usecols = n,n可以是数值、列表,列表中可以是数值也可以是字段名,表示想要读取的列
df = pd.read_csv("D:/pandas/TOP250.xlsx",usecols=[0,2,4]) #上述代码表示读取第一、第三和第五列 #假设第一、第三、第五列的列表名分别为: a,b,c。那么也可以如下代码表达: df = pd.read_csv("D:/pandas/TOP250.xlsx",usecols=['a','b','c'])index_col = n,可以是数值、列表,列表中可以是数值也可以是字段名,表示将n中字段设置为索引列
df = pd.read_csv("D:/pandas/TOP250.xlsx",index_col=0) #将第一列作为索引列 df = pd.read_csv("D:/pandas/TOP250.xlsx",index_col='a') #若第一列列名为a,也可以表达为上述代码dtype = {'a':'b',":"},dtype表示字段格式,其中a表示字段名,b表示字段类型
df = pd.read_csv("D:/pandas/TOP250.xlsx",dtype={'test1':'str','test2':'int'}) #将test1列设置成字符串格式,将test2列设置成int格式parse_data = ['','',...],parse_data表示将字段转化成日期格式
df = pd.read_csv("D:/pandas/TOP250.xlsx",parse_dates=['date_1']) #表示将date_1的格式转化成日期格式 print(df.dtypes) #结果中有:date_1 datetime64[ns] #说明date_1是日期格式二.读取指定文件夹下的文件
例如:在我的test文件夹中有n个相同类型的xlsx文件,我想将其合并,有如下两种方法
方法一:
import pandas as pd import os path = 'D:/pandas/test/' #path文件夹具体位置,文件夹下有你所需的多个xlsx文件 filenames = os.listdir(path) #filename为path下所有的文件的文件名,以列表形式输出 filenames = [i for i in filenames if i.lower().endswith('.xlsx)] #这行代码是为了得到以.xlsx为结尾的文件名,并形成列表 lis = []#创建一个新列表,用于放数据 for i in filenames: lis.append(pd.read_excel(path + filename)) #遍历文件,通过pd.read_excel读取xlsx文件并通过append合并 df1 = pd.concat(lis) #将列表lis合并生成一个文件 df1.to_excel(存放地址,index=False) #保存文件 方法二:
import glob import pandas as pd import os paths = glob.glob("D:/pandas/test/*.xlsx") #表示读取test文件下所有的.xlsx文件,生成列表 data1 = pd.DataFrame() #创建一个新的DataFrame框架 for path in paths: data = pd.read_excel(path) data1 = pd.concat([data1,data]) #遍历文件读取并合并,放入data1中,生成一个新的合并后的文件 df.to_excel(存放地址,index=False)热门文章
- 动物打疫苗在哪打的 动物打疫苗在哪打的啊
- 「1月31日」最高速度21.7M/S,2025年Nekoray每天更新免费机场订阅分享
- 「11月8日」最高速度22.3M/S,2024年Nekoray每天更新免费机场订阅节点链接
- 「12月30日」最高速度18.3M/S,2024年Nekoray每天更新免费机场订阅分享
- 「11月29日」最高速度21.9M/S,2024年Nekoray每天更新免费机场订阅节点链接
- 上海农业大学动物医院官网(上海农业大学动物医院官网招聘)
- 猫咪疫苗三针打完后多久再打(猫咪疫苗三针打完后多久再打第三针)
- 致命行动(致命行动电视剧大全)
- 国内前十名的兽药厂家排名(国内十大兽药厂排名)
- 「1月13日」最高速度19.1M/S,2025年Nekoray每天更新免费机场订阅分享